
Google DeepMind ha decidido intervenir en uno de los debates más resbaladizos de la industria: cómo medir de forma empírica el progreso hacia la AGI. En un mercado donde cada salto de modelo tiende a presentarse como un punto de inflexión, disponer de una métrica más estable resulta casi tan importante como el propio avance técnico.
La compañía ha presentado un marco cognitivo para evaluar sistemas de IA en relación con habilidades humanas y, al mismo tiempo, ha puesto en marcha un hackathon con Kaggle para diseñar pruebas en las áreas donde hoy existen más lagunas. La novedad no está solo en la lista de capacidades, sino en el intento de convertir una discusión dominada por afirmaciones vagas en un problema de medición.
El paper, Measuring Progress Toward AGI: A Cognitive Framework , parte de una premisa incómoda para el sector: no existe todavía un método claro y compartido para determinar hasta qué punto un sistema se aproxima a una inteligencia general comparable a la humana. Esa ambigüedad, sostienen sus autores, alimenta tanto la sobreestimación como la infravaloración de los modelos actuales, y complica desde la comunicación científica hasta el diseño de políticas públicas. No es una discusión filosófica aislada. También afecta a la gobernanza, a la compra de tecnología y a la forma en que empresas y administraciones interpretan riesgos y capacidades reales.
Progreso hacia la AGI: de la intuición a la taxonomía
La propuesta de Google DeepMind descompone la inteligencia general en diez facultades cognitivas. Ocho funcionan como bloques básicos: percepción, generación, atención, aprendizaje, memoria, razonamiento, metacognición y funciones ejecutivas. A ellas suma dos facultades compuestas, resolución de problemas y cognición social, que intentan capturar situaciones en las que varias capacidades actúan de forma coordinada. La idea central es sencilla de formular, aunque mucho más difícil de ejecutar: si un sistema aspira a un comportamiento general, no basta con que destaque en unas pocas tareas espectaculares; debe exhibir un perfil suficientemente sólido a lo largo de todo ese espacio cognitivo.
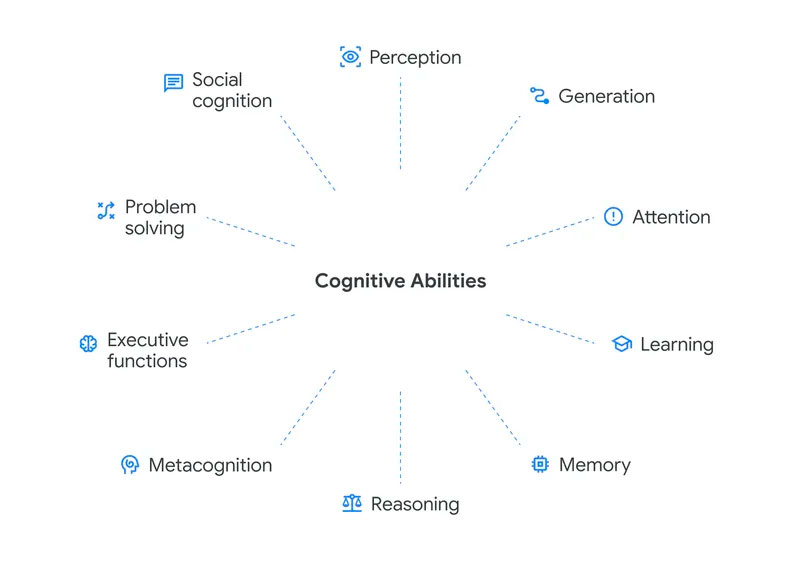
Ese punto es relevante porque el debate sobre AGI suele quedar atrapado entre demostraciones puntuales y comparativas comerciales. Un modelo puede escribir código con soltura, resumir documentos o resolver ciertos exámenes, y aun así mostrar debilidades severas en memoria episódica, control atencional o planificación. El paper insiste en esa naturaleza «dentada» de las capacidades de los sistemas actuales: avances muy visibles en unas áreas conviven con fallos persistentes en otras. En ese sentido, la taxonomía no busca declarar ganadores, sino dibujar perfiles de fortalezas y debilidades frente a una distribución de rendimiento humano.
Hay otro matiz importante. El marco se centra en lo que un sistema puede hacer, no en cómo lo hace. Esa elección evita atar la evaluación a una arquitectura concreta y permite comparar modelos y sistemas con diseños distintos. También refleja una realidad industrial: la carrera por la IA generativa se mueve demasiado rápido como para construir un estándar que dependa de mecanismos internos que cambian cada pocos meses. El enfoque, por tanto, es funcional. Eso le da flexibilidad, aunque también introduce una tensión: medir desempeño sin entrar en la mecánica interna puede ser útil para comparar, pero no siempre basta para explicar por qué un sistema falla.
Progreso hacia la AGI: cómo quiere evaluarlo Google
La parte más ambiciosa del documento está en el protocolo de evaluación. DeepMind plantea tres pasos.
- Evaluar sistemas en una batería amplia de tareas cognitivas específicas, idealmente con conjuntos de prueba reservados para evitar contaminación de datos.
- Escoger líneas base humanas con una muestra demográficamente representativa de adultos, al menos con el equivalente a educación secundaria superior.
- Situar a cada sistema dentro de la distribución de rendimiento humano para cada facultad y construir así un «perfil cognitivo».
La comparación con humanos es el núcleo del planteamiento. No se trata solo de saber si un modelo responde bien o mal, sino de estimar a qué porcentaje de personas superaría en cada dimensión. Sobre el papel, esto permite salir de la lógica binaria del «nivel humano» y reemplazarla por una gradación más informativa. Un sistema podría situarse por encima de la mediana humana en todas las facultades y seguir lejos de los percentiles más altos. O podría brillar en razonamiento y memoria semántica mientras cae por debajo de la media en cognición social o aprendizaje continuo. Esa granularidad tiene valor técnico, pero también comercial y regulatorio. Obliga a hablar de capacidades concretas, no de etiquetas totales.
El problema es que convertir esa idea en una infraestructura de pruebas fiable exige resolver varios obstáculos. El paper identifica al menos tres fuentes de incertidumbre: la calidad de las tareas, la validez del constructo y la estocasticidad de los sistemas generativos. En términos prácticos, una mala batería de pruebas puede medir otra cosa distinta de la que dice medir; una prueba demasiado pública puede estar contaminada; y un modelo puede ofrecer resultados muy dispares entre una ejecución y otra. No son detalles metodológicos menores. Son el tipo de problemas que han erosionado la credibilidad de muchos benchmarks en los últimos años.
Ahí encaja el hackathon lanzado con Kaggle. Google y Kaggle buscan que la comunidad diseñe evaluaciones para cinco áreas donde reconocen un déficit especial: aprendizaje, metacognición, atención, funciones ejecutivas y cognición social. Habrá premios económicos y una ventana de presentación entre el 17 de marzo y el 16 de abril, con resultados previstos para el 1 de junio, según el anuncio difundido por la compañía. La decisión tiene lectura doble. Por un lado, externaliza parte del trabajo más difícil: crear pruebas robustas y novedosas. Por otro, convierte la falta de métricas en un problema abierto de ecosistema, no solo de laboratorio interno.

Lo que el marco incluye, y lo que deja fuera
El propio paper admite que medir facultades cognitivas no basta para capturar todo lo que importa en un sistema avanzado. DeepMind señala varias dimensiones adicionales: velocidad de procesamiento y respuesta, propensiones del sistema, creatividad y evaluaciones de despliegue de extremo a extremo. La distinción es significativa. Un modelo puede ser correcto pero demasiado lento para un entorno operativo. Puede rendir bien en pruebas aisladas y, sin embargo, exhibir tendencias problemáticas al interactuar con usuarios o asumir riesgos. Puede mostrar recursos creativos difíciles de encajar en categorías clásicas.
También aparece una discusión que toca una fibra sensible del sector: si debe evaluarse el modelo o el sistema completo. DeepMind se inclina por lo segundo. Tiene lógica. Los productos reales incorporan instrucciones, herramientas externas, acceso a buscadores, módulos adicionales y, cada vez más, capacidad de actuar sobre entornos. Evaluar solo el checkpoint desnudo puede resultar artificial. Aunque esa decisión complica la interpretación. Si un sistema resuelve una tarea porque usa herramientas externas, ¿estamos midiendo memoria, búsqueda o diseño del entorno? El documento no cierra del todo esa cuestión, pero deja claro que la comparación solo será honesta si humanos y sistemas operan con condiciones equivalentes.
Para las empresas, el interés del marco no reside únicamente en la discusión sobre AGI. También ofrece una posible gramática común para comprar, auditar o desplegar IA. En lugar de aceptar promesas genéricas sobre «agentes inteligentes», un responsable de tecnología podría preguntar por perfiles de atención, planificación, aprendizaje o memoria según tareas concretas. Eso no elimina la opacidad del mercado, aunque introduce una demanda de precisión que hasta ahora ha sido irregular.
Medir mejor no va a zanjar por sí solo el debate sobre la AGI. Sí puede cambiar su tono. Un marco basado en perfiles cognitivos comparados con humanos reduce el margen para las afirmaciones totales y desplaza la discusión hacia déficits concretos, capacidades parciales y condiciones de uso.
A partir de ahí se abre otra disputa, menos visible pero igual de decisiva: quién diseña las pruebas, quién controla los conjuntos reservados y bajo qué criterios se considera que un sistema supera el rendimiento humano. La medición puede ordenar la conversación. También puede convertirse en otro terreno de competencia entre laboratorios, plataformas y organismos reguladores.
