El desarrollo de productos basados en grandes modelos de lenguaje no puede abordarse como la simple integración de un algoritmo aislado. Requiere una visión de sistema en la que intervienen múltiples componentes técnicos y organizativos que se combinan de forma estructurada.
El llamado stack de IA generativa actúa como ese mapa arquitectónico: agrupa la infraestructura de computación en la nube, los modelos fundacionales, las capas de orquestación, las bases de datos vectoriales, los mecanismos de supervisión y las políticas de seguridad. Cada nivel cumple una función específica y está interconectado con los demás, lo que significa que una decisión en un punto repercute en la eficiencia, el coste y la gobernanza global del sistema. Para las empresas en España, comprender qué aporta cada capa, qué dependencias introduce y cómo se acopla a los procesos corporativos resulta imprescindible si se quiere avanzar hacia despliegues operativos sostenibles y conformes con las normativas vigentes.
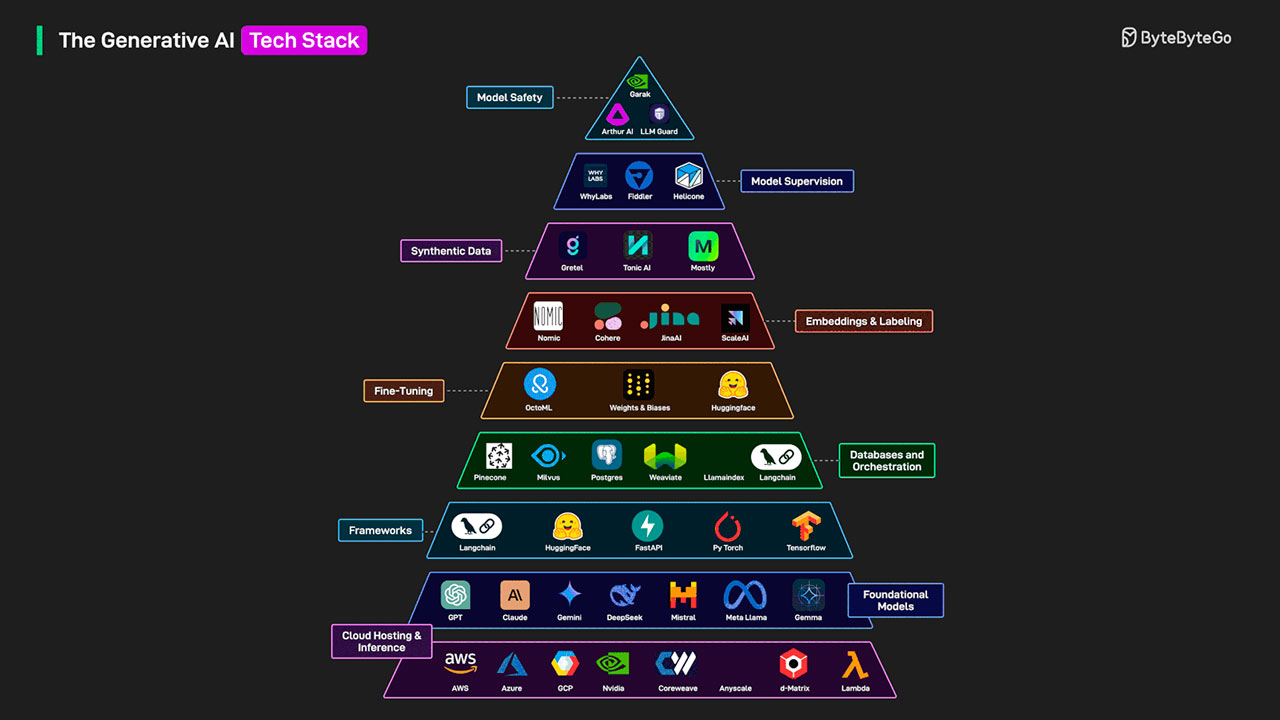
Un esquema sintético del sector sitúa la base en la infraestructura de nube y, a partir de ahí, ocho capas funcionales que culminan en seguridad y gobernanza del modelo. La fotografía de proveedores que se citan a continuación procede del gráfico de ByteByteGo, que agrupa a compañías representativas por función. El detalle exacto de herramientas en cada capa cambia con rapidez, pero la lógica técnica del apilamiento se mantiene estable: cada nivel encapsula capacidades y costes distintos y condiciona decisiones aguas arriba.
Capa 1: Cloud hosting e inferencia en la nube
El primer bloque reúne a los proveedores que suministran computación, redes y almacenamiento para entrenamiento e inferencia: AWS, Azure, Google Cloud y opciones centradas en hardware como NVIDIA u otros operadores. A escala corporativa, aquí se deciden:
- Arquitectura de cómputo (GPU, CPU, aceleradores específicos).
- Topología de redes y proximidad a datos corporativos.
- SLA y continuidad de negocio: redundancia multirregión, recuperación ante desastres.
- Costes unitarios por token/segundo y políticas de autoscaling para picos de consulta.
Estas decisiones afectan directamente a latencia, coste por interacción y capacidad de cumplir con requisitos de residencia y soberanía del dato.
Capa 2: Modelos fundacionales
Sobre la infraestructura se sitúan los modelos preentrenados: ChatGPT, Claude, Gemini, Mistral, DeepSeek, Meta Llama o Gemma, entre otros. Son motores generalistas con capacidades de razonamiento y generación que se consumen como servicio o se autogestionan. Aspectos a evaluar:
- Licencias y restricciones de uso (comercial, weights abiertos o cerrados).
- Compatibilidad con despliegue on-prem o VPC.
- Idiomas y dominios cubiertos con calidad suficiente para el caso de negocio.
- Formato de entrada/salida y límites de contexto.
La elección no es exclusivamente técnica: condiciona costes operativos, vías de ajuste fino y dependencia del proveedor.
Capa 3: Frameworks y orquestación de agentes
Herramientas como LangChain, Hugging Face, FastAPI, PyTorch o TensorFlow estructuran la interacción con los modelos y encapsulan flujos de trabajo, chains y agentes. Este nivel facilita:
- Integrar pasos de recuperación, llamada a herramientas y control de estado.
- Definir interfaces API reproducibles y pruebas automatizadas.
- Acelerar prototipado sin bloquear el cambio de modelo.
Para entornos regulados, es clave garantizar observabilidad del grafo de llamadas y trazabilidad de versiones.
Capa 4: Bases vectoriales y RAG
El almacenamiento y orquestación de contextos se apoya en bases vectoriales como Oracle, Pinecone, Weaviate, Milvus y en capas de indexación como LlamaIndex. Son piezas centrales para RAG (recuperación aumentada por generación) y agentes con “memoria”. Variables técnicas:
- Calidad de embeddings y tamaño del índice.
- Estrategias de particionado, sharding y replicación.
- Funciones de búsqueda (kNN, hybrid search, reranking).
- Consistencia y frescura del contenido actualizado.
Una orquestación robusta minimiza alucinaciones al inyectar evidencias verificables en la ventana de contexto.
Capa 5: Ajuste fino y gestión del ciclo de vida
Plataformas como Weights & Biases, Hugging Face u OctoML ayudan a organizar experimentos, fine-tuning, versiones y seguimiento de métricas. Para las empresas, el foco está en:
- Datasets internos curados y su gobernanza.
- Técnicas de ajuste (LoRA, instruction tuning, domain adaptation).
- Evaluaciones continuas con benchmarks propios y golden sets.
- Reproducibilidad: semillas, pipelines declarativos y model cards.
El ajuste fino solo aporta valor cuando se demuestra mejora en tareas específicas frente a alternativas como RAG o prompt engineering.
Capa 6: Embeddings y etiquetado
Herramientas como Cohere, JinaAI, Nomic o servicios de Scale AI convierten textos e imágenes en vectores y facilitan anotación supervisada. Puntos prácticos:
- Dimensionalidad y coste de los embeddings frente a precisión semántica.
- Calidad de anotación (inter-anotador, guías, control estadístico).
- Privacidad: tratamiento de datos personales y minimización.
La elección del modelo de embedding repercute en el rendimiento de la búsqueda y en el tamaño del índice vectorial.
Capa 7: Datos sintéticos
Gretel, Tonic AI o Mostly ofrecen generación de datos simulados para entrenamiento, pruebas o stress testing cuando el acceso a datos reales es limitado o sensible. Consideraciones:
- Medidas de privacidad (riesgo de reidentificación, métricas de similitud).
- Representatividad de escenarios raros para robustez.
- Trazabilidad para separar claramente datos reales y sintéticos en auditorías.
Su uso debe ir acompañado de validaciones que demuestren que el modelo no memoriza patrones falsos o sesgados.
Capa 8: Supervisión del modelo
La monitorización y la trazabilidad del comportamiento de modelos y pipelines recaen en proveedores como WhyLabs, Fiddler o Helicone. Funciones típicas:
- Trazas de prompts y respuestas con metadatos (latencia, tokens, tools).
- Drift de datos y alertas sobre degradación.
- A/B testing y evaluación en producción con conjuntos de referencia.
- Cuadros de mando para equipos técnicos y de negocio.
El objetivo es convertir la operación del sistema en un proceso medible y auditable.
Capa 9: Seguridad y cumplimiento del modelo
En el vértice aparecen LLM Guard, Arthur AI o Garak con mecanismos de filtrado de entradas y salidas, detección de prompt injection, validación de contenidos y cumplimiento normativo. A nivel empresarial conviene:

- Políticas de guardrails por dominio (contenido sensible, finanzas, salud).
- Verificación de herramientas invocadas por agentes (listas blancas y sandboxing).
- Registro de decisiones para auditorías internas y regulatorias.
Estas medidas no sustituyen controles administrativos: se complementan con formación, segregación de datos y revisiones de terceros.
Criterios de decisión para empresas en España
Las organizaciones que evalúan proyectos de IA generativa suelen partir de cuatro ejes:
- Gobernanza y cumplimiento: coordinación con seguridad de la información, DPO y asesoría jurídica. En Europa, el Reglamento de IA exigirá clasificación de riesgos, documentación técnica y supervisión humana en determinadas categorías, lo que favorece soluciones con trazabilidad y control de datos.
- Residencia y soberanía: requisitos de localización de datos y mecanismos de seudonimización; compatibilidad con VPC, private links y cifrado gestionado por el cliente.
- Impacto económico: cálculo del coste por interacción (tokens de entrada y salida, reranking, llamadas a herramientas) y del TCO del índice vectorial, además de gastos de red y observabilidad.
- Modelo operativo: quién opera el sistema (equipo interno, partner o proveedor), acuerdos de nivel de servicio y capacidad de reversibilidad.
Métricas operativas a vigilar
Para que el stack sea gestionable, conviene estandarizar un cuadro de métricas:
- Latencia P50/P95 por tipo de prompt y por capa.
- Tasa de éxito de herramientas invocadas por agentes.
- Tasa de respuestas citadas y cobertura de fuentes en RAG.
- Degradación por drift y alertas de anomalías.
- Coste por transacción desglosado por componente (modelo, vector DB, reranker).
- Riesgos: eventos de prompt injection, datos sensibles detectados, rate limits superados.
Estas métricas alimentan SLOs y revisiones periódicas con negocio.
Riesgos, costes y dependencia del proveedor
El diseño del stack debe gestionar tres frentes:
- Bloqueo tecnológico: abstracciones que permitan cambiar de modelo, reutilizar embeddings o migrar de base vectorial. La compatibilidad a nivel de API reduce el coste de salida.
- Escalabilidad económica: mecanismos de caché, compresión de contexto y batching para aplanar costes. En lotes masivos, evaluar inferencias offline frente a peticiones en línea.
- Seguridad de datos: minimización, separación de entornos, controles de acceso finos y auditoría. Las pruebas de red-teaming deben ser recurrentes.
Hoja de ruta para un despliegue gradual
Un enfoque por fases reduce riesgo y acelera el aprendizaje organizativo:
- Caso de uso acotado con RAG sobre un corpus bien curado y métricas claras.
- Instrumentación exhaustiva desde el principio: prompt tracing, evaluación automatizada y panel de costes.
- Iteraciones sobre prompts y recuperación antes de considerar el ajuste fino.
- Políticas de guardrails: filtrado de entradas, clasificación de salidas y control de herramientas.
- Revisión de cumplimiento y procedimientos de retirada rápida del servicio ante incidencias.
- Escalado a nuevos dominios con reutilización de componentes (índices, pipelines, test suites).
Lectura del gráfico sectorial
El mapa de ByteByteGo —mencionado más arriba— sitúa a cada proveedor en una única capa para facilitar la comprensión, pero en la práctica las fronteras son porosas. Varias compañías operan en más de un nivel (p. ej., modelos y embeddings, o base vectorial y reranking). Para el lector corporativo, la utilidad del esquema está en visualizar dependencias, evitar solapamientos y fijar responsabilidades por capa: quién elige, quién opera y cómo se mide.
Qué debe esperar dirección de tecnología
De cara a comités de inversión y consejos de administración, el stack de IA generativa se alinea con prácticas de ingeniería conocidas: diseño modular, observability by default, pruebas automatizadas y control de cambios. La diferencia radica en la naturaleza probabilística de los modelos y en la necesidad de evaluaciones continuas fuera de laboratorio. Por ello, la supervisión y la seguridad se colocan al final del apilamiento, no como anexos, sino como capas permanentes del sistema.
Claves para una adopción sostenible
- Tratar el modelo como un componente más, no como el sistema completo.
- Priorizar datos gobernados y golden sets que permitan medir progreso.
- Documentar decisiones de arquitectura y matrices de riesgos por caso de uso.
- Mantener portabilidad: APIs estándar, contracts de embeddings y exportación de índices.
- Integrar personas y procesos: revisión humana donde proceda, formación y protocolos de incidente.
Con este diseño, el despliegue de soluciones de IA generativa pasa de la experimentación aislada a plataformas reutilizables y auditables, con costes previsibles y controles claros.
